
Whatever your organisation’s performance or cost needs, Google Cloud is an eminently flexible platform that supports many different kinds of application architectures.
As cloud migration is order of the day and there are a few players with solid solutions in the market, customers will be naturally perplexed to take a decision. They will have to confront the question where should the journey begin?
As part of NFAPost initiative for beginners, we have covered some common Google Cloud reference architectures and have regrouped them all here. It will give a fare idea on how to deploy hybrid cloud or mobile apps, microservices, CI/CD, machine learning, or security.
1. Set up a hybrid architecture on Google Cloud and on-premises

When it comes to migration or just running part of the applications on-prem and the other part in cloud, hybrid architectures are pretty common. A very common hybrid architecture is where you have the frontend and/or application server deployed on Google Cloud and the backend on-prem.
In that scenario a user requests the apps over the internet and a global load balancer routes them to your application on Google Cloud or on-prem.
From there the global load balancing distributes the traffic to load balance to the appropriate service. Services can be on any compute platform such as Compute Engine, Google Kubernetes Engine (GKE), App Engine, etc.
The applications that need to talk to the backend systems in your data center must connect via Cloud VPN or Interconnect, depending on your bandwidth needs. Not sure which one to choose?
Requests for the on-prem application land on the load balancer, which distributes load across the application servers.
Application servers connect to backends such as search, cache and a database to fulfill the user’s request.
2. Set up a hybrid architecture for cloud bursting

Bursting traffic to the cloud can be a great way to start using cloud. If your application is deployed on-prem, you can use it for the baseline load and burst to Google Cloud temporarily when you need extra capacity due to a sudden increase in traffic.
The main reason to do this would be to avoid maintaining extra capacity on-prem. And because in the cloud you only pay for what you use, bursting can lead to cost savings.
3. Mask sensitive data in chatbots using Data Loss Prevention (DLP) API
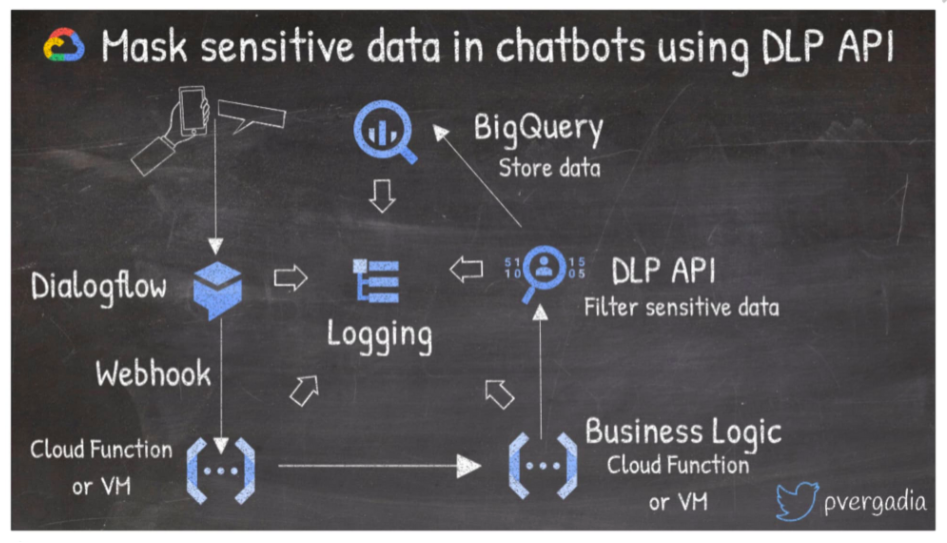
Imagine a situation where your business or users require sharing sensitive information with a chatbot. To do so, you can use Dialogflow, which helps create conversational experiences for your users without having to learn machine learning or artificial intelligence.
For example, in this architecture, the user interacts with a chat experience on a phone or the web, which calls the Dialogflow agent. The request gets fulfilled by business logic using serverless Cloud Functions or virtual machines. Then, if you want to de-identify sensitive information from the chat experience, you can use the DLP API and store it to BigQuery for further processing.
4. Build mobile app backends on Google Cloud

When building mobile apps on Google Cloud, Firebase is a good option for storage, user authentication, hosting and more.
You can integrate Firebase with multiple backends such as serverless Cloud Functions to glue together business logic or Cloud Run to run serverless containers as app backends. You can also connect with App Engine and Compute Engine, if that’s where your backends exist.
5. Migrate Oracle Database to Spanner
What’s the best way to migrate Oracle to Cloud Spanner? If you’re using an Oracle database and are looking to migrate it to Spanner for its global scale, you first need to export your Oracle database to a portable file format such as CSV and store it in Cloud Storage.
Then, ingest the data into Dataflow where you will read and parse the files, convert the data and construct Spanner mutations, handle any errors and finally write to Spanner.
6. Build a data lake in Google Cloud

The purpose of data lake is to ingest data and store it for mining and other workflows like data marts, real time analytics, ML and more! Here are some things to consider when setting up a data lake in Google Cloud:
You can ingest data from different sources such as (IoT) sensors, on-prem, user activity like clickstreams, online transactions, etc.
Real-time data can be ingested using Pub/Sub and Dataflow, which scale easily for varying data volumes.
Batch data can be ingested using Transfer Appliance, Transfer Service or gsutil, depending on your bandwidth and volume. The refined real-time data can be stored in Bigtable or Spanner.
You can mine the data in the data lake using Datalab and Dataprep. Or, for machine learning, use Datalab or ML Engine to train and store the predictions in Bigtable.
For warehousing you can send the data to BigQuery or, if you are a Hive ecosystem user, to Dataproc.
7. Host websites on Google Cloud

To scale a website based on traffic is not an easy task. Google Cloud offers simple and cost effective ways to host websites and scale to support large numbers of requests. Here’s how to scale a website on Google Cloud:
When a user sends a request to your website, Cloud DNS translates the hostname to your web server’s IP address.
Then the request goes to Cloud CDN, which responds from cache. If there is no cached response, then the request goes to Global Load Balancing which balances load across the web servers on Compute Engine. You can even set on-prem or another cloud as backends.
Static files such as images are served from Cloud Storage. Then the internal load balancer sends the request to the app servers and eventually to any databases.
Use the Firestore document database for user profiles and activities.
Use CloudSQL for relational data.
To protect your backend from layer 3 and 4 DDoS attacks, enable Cloud Armor with a global load balancer.
This example uses Compute Engine as a backend, but you can also deploy your backend in containers running on GKE, Cloud Run or App Engine.
To scale the infrastructure while using Compute Engine, use managed instance groups, which autoscale as load increases. (App Engine and Cloud Run scale with load automatically).
8.Set up a CI/CD pipeline on Google Cloud
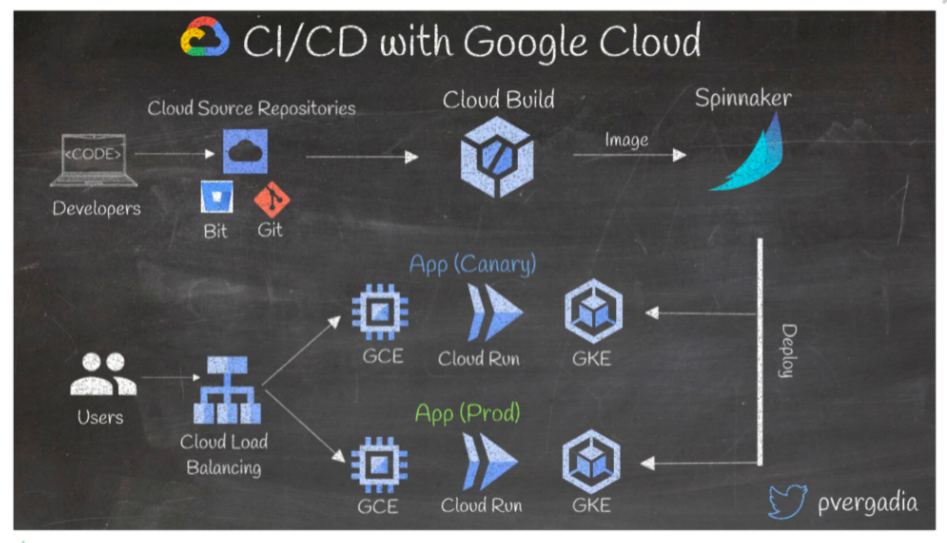
CI/CD is an effective way to make developers’ lives easier and to keep deployments sane. Setting up CI/CD with Google Cloud is simple:
Developers write the code and push it to Google Cloud source repositories, bitbucket or a git repo.
As soon as the code hits the repo, Cloud Build kicks in— it runs tests and security scans and builds a docker image, then pushes it to Spinnaker, an open-source multi-cloud continuous delivery platform (you can also use Jenkins or Gitlab).
Spinnaker then deploys the container to a production cluster on GKE, Cloud Run or Compute Engine; it can also deploy a canary app to ensure changes are tested against real traffic.
The incoming user traffic hits the load balancer and gets routed to the canary or prod app.
If the canary app turns out unsatisfactory, you can automate a quick rollback.
9. Build serverless microservices in Google Cloud
Microservices and serverless architectures offer greater scalability, more flexibility, and quicker time-to-release, all at a reduced cost. A good way to build a serverless microservice architecture on Google Cloud is to use Cloud Run. Let’s use an example of an e-commerce app:
When a user places an order, a frontend on Cloud Run receives the request and sends it to Pub/Sub, an asynchronous messaging service.
The subsequent microservices, also deployed on Cloud Run, subscribe to the Pub/Sub events.
Let’s say the authentication service makes a call to Firestore, a serverless NoSQL document database. The inventory service queries the DB either in a CloudSQL fully managed relational database or in Firestore. Then the order service receives an event from Pub/Sub to process the order.
The static files are stored in Cloud Storage, which can then trigger a cloud function for data analysis by calling the ML APIs.
There could be other microservices like address lookup deployed on Cloud Functions.
All logs are stored in Cloud Logging.
BigQuery stores all the data for serverless warehousing.
10. Machine learning on Google Cloud

Organisations are constantly generating data, and can use machine learning techniques to gain insights into that data. Here are the steps to accomplish machine learning on Google Cloud:
First, ingest the data using a Transfer Appliance or Transfer Service into Cloud Storage or BigQuery.
Then, prepare and pre-process the data with BigQuery, Dataprep, Dataflow or Dataproc.
Use AI Hub to discover the pipelines and AI content that already exists.
When ready, use AI Platform’s Data Labeling Service to label the data.
Build your ML application using managed Jupyter notebooks and a Deep Learning VM image.
Then use AI platform training and prediction services to train your model and deploy them to Google Cloud in a serverless environment or on-prem using Kubeflow.
Use explainable AI to explain your model results to business users, then share them on AI Hub for others to discover.
11. Serverless image, video or text processing in Google Cloud
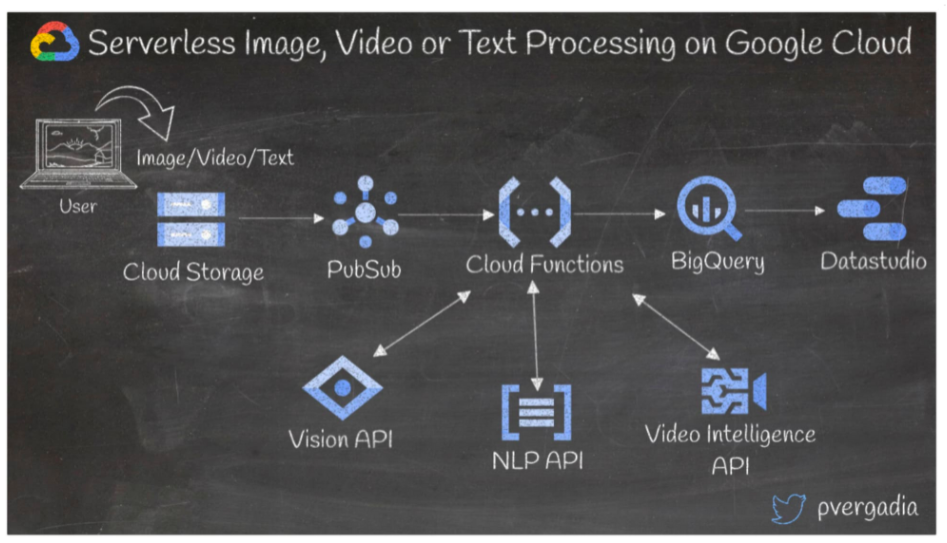
Most applications require a certain amount of image, video or text processing. In this architecture let’s assume a blogging website where users generate content in the form of videos, images and text.
User-generated content from the front end is stored in Cloud Storage, which creates a Pub/Sub event and triggers a cloud function.
Cloud Functions then calls the Vision API, Video Intelligence API or the NLP API, depending on the type of file uploaded by the user.
The cloud function receives a JSON response from the respective ML API, processes the findings further and sends the results to BigQuery for further analysis.
Google Data Studio or another visualisation tool can be used to create custom dashboards to analyze the trends.
12. Internet of Things (IoT) on Google Cloud

If you have a large number of devices that generate data, you can use IoT workflows to easily and securely connect, manage, and ingest data to utilise it for downstream applications. Here’s a sample IoT workflow on Google Cloud.
A sensor sends data to an edge device equipped with an Edge TPU, a chip that runs ML models on the edge.
There, the Cloud IoT Edge software layer lets you execute ML models and run on Android Things or Linux OS.
From the edge device the data is sent to Cloud IoT Core over MQTT or HTTP(S), which creates events in Pub/Sub.
Pub/Sub then triggers Cloud Functions to update any device configurations.
For long term storage, Dataflow filters and processes the data and sends it to a Bigtable NoSQL database or BigQuery.
From BigQuery, you can train a machine learning model using either BigqueryML or AI Platform.
You can visualise the data in Data Studio or another dashboard.
13. Set up the BeyondCorp zero trust security model

BeyondCorp is Google’s implementation of a zero-trust security model. It builds upon eight years of building zero-trust networks at Google, combined with ideas and best practices from the community. Let’s take an example of a company where an employee is trying to access an internal app.
The request goes to Cloud Load Balancing which sends it to an Identity Aware Proxy (IAP).
IAP then connects to the device inventory and checks if the user is legitimate, connects to Cloud identity for endpoint management, Active Directory for authentication, Identity and Access Management (IAM) and Access Context Manager for policy-based contextual access. These checks can be configured differently for an employee vs a contractor.
Once passed, the checks are routed to the service. If the checks aren’t passed, the user is denied access.
If the backend is on-prem then IAP on-prem connector and Cloud Interconnect, or Cloud VPN, connect directly to the datacenter.
I do hope that the post will provide a good sense of how to kickstart your journey to Google Cloud. (And of course, please note that these are just examples, and that each of the solutions can be achieved in more than one way.)


